2021. 1. 7. 16:43ㆍ딥러닝 강의 정리
Divergence
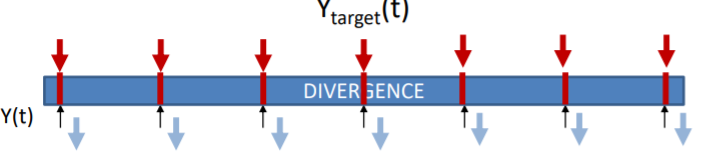
RNN에서 가장 애매한 부분이 divergence를 정의하는 것이다. output을 시간별로 끊어서 봐야할지 통째로 봐야할지 애매하기 때문이다. 먼저 MLP Processing을 보자.

이것은 사실 RNN이라고 할 수는 없다. Recurrence하지 않고 각각이 individual하기 때문이다. 따라서 각각의 시간별로 output은 그 전시간의 output과 관련이 없어 따로 생각하면 된다.
우리가 backpropagation으로 찾으려 하는 것은 이며 이는 DIV가

이렇게 각시간별로 따로 divergence를 곱한다음 그것의 weighted sum임으로 이것을 미분하면

가 나옴을 알 수 있다. 그리고 일반적으로 divergence function으로는 Xent function인 cross entophy를 사용한다.

이를 아래의 RNN에도 똑같이 적용하기에는
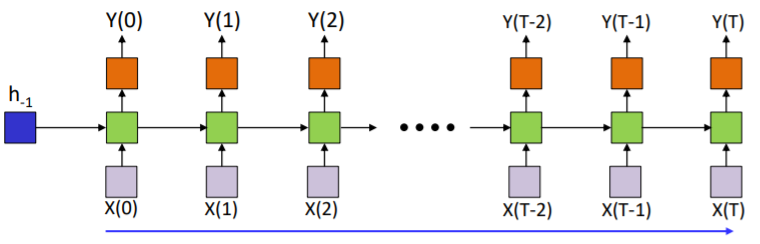
이경우는 과거의 data역시 현재의 ouput에 영향을 미치기 때문에 divergence를 그냥 각각의 weighted sum으로 두기가 어렵다. 하지만 이때도 역시 그냥 위와 같이 weighted sum이라고 가정을 한다음 진행을 한다.

그래서 이때도 역시 로 두고 계산을 한다.
Simple Recurrence Example : Text Modeling
RNN의 각각의 output은 다음에 나올 것을 예측하는 것이다. text를 예를 들어보면 t=0일때 w_0을 넣으면 그때의 output은 w_1을 예상하는 형식이다.

이때 각각의 input은 one-hot vector로 넣어야 하며 output은 각각의 글자가 나올 확률로 나오게 된다. 예를들어 "hello"라는 단어를 넣었을 때 input으로 각각의 글자를 쪼개서 h:[1 0 0 0], e:[0 1 0 0], l:[0 0 1 0], o:[0 0 0 1]로 두고 넣으면 output은 예를들어 softmax인 [1.0, 2.2, -3.0, 4.1]이 나와 가장 높은 숫자인 2.2를 택하고 그것에 맞는 글자인 e를 선택하는 식이다.

이제 Divergence를 직접 구해보자

위의 경우가 있다고 가정하면

임으로 target값의 위치의 확률만 남게 된다. 따라서 전체적인 div는 아래와 같다.

One-hot Vector
영어를 RNN으로 하려면 약 100개의 글자를 가지고 학습해야 한다고 한다. (대문자, 소문자, 콤마등). 이를 one-hot vector로 나타내면 [0 0 0 0 0 1 0 0 0.....]이렇게 100개의 열을 가지고 있는 벡터를 input으로 넣어야 한다.

여기서 Dimensionality problem이 생기게 된다. 모든 input들은 영어를 예로 들면 100차원의 input을 가지고 있고 이것들은 매우 sparse하다. 100차원 안에는 개의 경우의 수가 있고 우리가 실질적으로 사용하는 것은 [1 0 0 0 ...]등 100개의 열중 오직 하나만 1인 경우만 사용한다. 그니깐 [1 0 0 1 0 1...]이런식의 벡터는 사용하지도 않는다는 것이다. 이것은 매우 비효율적인 문제이다. 그렇다면 이렇게 비효율적인데도 one-hot vector를 사용하는 이유는 무엇일까?

위의 3차원의 공간에서 예를 들어보면 각각의 점들은 모두 거리가 1이고 one-hot vector들끼리의 거리는 항상 이다. 컴퓨터는 실질적인 언어를 알지 못한다. 각각의 저럼 점들을 가지고 패턴을 파악할 뿐이다. one-hot vector에서는 항상 모든 input의 점들의 거리가 일정하니깐 그 어느 input에게도 힘을 실어주지 못하고 모두 같은 위치에서 시작할 수 있게 된다. 따라서 모두에게 같은 중요도를 부과한다는 것이다.
하지만 이렇긴해도 여전히 공간을 효율적으로 쓰지 못한다는 단점이 있다. 그래서 이를 해결하기 위해 좀더 낮은 차원으로 projection을 해서 사용한다.

이렇게 하면 project된 차원안에서는 좀더 효율적으로 공간을 사용할 수 있게 된다. 그렇다면 이런 hyper plane은 어떻게 구할 수 있을 까? 이것 역시 training을 통해서 얻어낼 수 있다.

N차원을 M으로 project할때 layer가 1개이고 input이 N, output이 M인 퍼셉트론을 만들고 projection이 linear한 것이니 activation을 linear activation을 사용한다.
Generating Language Model

위에서 hidden unit은 LSTM unit이라고 하자. 이 모델을 이용해서 문장을 생성하려고 한다. 우선 이 모델로 굉장히 많은 양의 정보를 학습 시킨다. 그다음 학습이 끝나면 아래처럼 몇단어만 제시를 해준다.

3단어를 제시해주면 마지막 output은 4번째 단어의 예측을 담고 있는데 이를 input으로 넣어 새로운 문장을 만들어 내는 것이다.

Many to One
지금까지는 many to many 모델을 주로 살펴 보았다. 이번에는 many to one model을 살펴보자.

이 모델은 질문에 답하는 것에 주로 사용된다. 위에서 하늘의 색을 input으로 넣었으면 맨 마지막 output으로 답을 말하는 구조이다. 위의 구조에서 첫번째와 두번째의 output도 나오기는 하지만 맨 마지막만 읽는 것이다.
그렇다면 이 구조의 divergence는 어떻게 구해야 할까?

위와 같이 하나의 final output이 모든 파라미터를 update하는 구조 이다. 이는 너무 복잡하다. 그래서

이렇게 사용하지 않는 output도 divergence구하는데 사용한다. 이때의 divergnece는 아래와 같다.
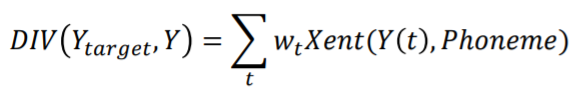
그리고 이 식에서 가중치 w를 output마다 다르게 주는 것이다. 우리는 마지막 output에만 관심있음으로 거기에만 가중치를 1주고 나머지는 0을 주면 좀더 손쉽게 divergence를 구할 수 있게 된다.
'딥러닝 강의 정리' 카테고리의 다른 글
| Sequence to Sequence Models : Attention Models /Lec 13. (0) | 2021.01.08 |
|---|---|
| Sequence to Sequence Models/Lec.12 (0) | 2021.01.07 |
| Recurrent Networks: Stability analysis and LSTMs/ Lec.11 (0) | 2021.01.06 |
| Recurrent Networks 1/Lec. 10 (0) | 2021.01.06 |
| Convolutional Networks 3/ Lec.09 (0) | 2021.01.05 |