2021. 2. 21. 01:55ㆍ논문 정리
논문 제목 : Faster R-CNN : Towards Real-Time Object Detection with Region Proposal Networks
INTRODUCTION
기존의 object detection들(Fast R-CNN,,,)은 region proposal 과정에서 시간을 너무 많이 소비하였다. Fast R-CNN은 region proposal을 selective search의 방법을 사용하였는데 이는 CNN의 외부에서 이루어지고 CPU를 기반으로 작동되었다. 이것이 시간 소비의 주범이였다. 그래서 region proposal의 방식을 region proposal network를 이용하여 구하는 것이 제시가 되었다.

이 방법은 그저 몇개의 convolution lyaer를 더해서 regress region bound 와 obejectness score를 계산하는 것임으로 그렇게 계산량이 많지도 않고 비교를 하자면 VGG에서 맨 마지막의 Fully connected layer정도의 수준이다.
또한 기존의 연구들은 pyramid of images를 가지고 각각 계산을 한다면 이 연구에서는 anchor box의 도입으로 계산량을 줄였다. 이는 후에 자세하게 설명이 될것이다.
이 Faster R-CNN으로 ILSVRC, COCO에서 굉장히 좋은 성적을 거둘 수 있었다.
FASTER R-CNN
기본적으로 Faster R-CNN은 2개의 stage로 구성된다. deep fully convolution network의 결과를 이용해 region proposal + Fast R-CNN이다. (attention mechanism이 어디에 사용될까?)
1. Region Proposal Networks(RPN)
이미지를 input으로 받고 object proposal을 output으로 내보낸다. 그리고 각각의 output에는 objectness score, 즉 object가 있는지 없는지에대한 값이 들어있다.
모델은 fully convolution network(FCN)로 구성되어있는데 이는 Fast R-CNN과의 share computation을 위해서이다.
FCN은 아래 그림처럼 fully connected layer를 conv layer로 바꾼것이다.

convolution 자체가 위치정보를 기억할 수 있음으로 region proposal을 효과적으로 수행할 수 있는 것이다.
RPN 수행하는 방법은 1) 우선 이미지를 커다란 Conv net으로 돌려서 feature map을 구한다. 2) 그 feature map을 slide window 방식으로 각각 FCN을 돌린다. 이때 두개의 FCN으로 들어가는데 하나는 box regression(reg), 다른 하나는 box classification(cls)이다.
1-1. Anchors
slide window를 할때 anchor라는 개념이 새로 등장한다. anchor는 proposal box의 틀인데 scale과 ratio로 구성되어있다. 일반적으로는 3 scales and 3 aspect ratio로 사용한다. anchor box의 총 갯수를 k라고 하는데 3 scale, 3 ratio로 만들면 k = 9가 나오게 된다. 즉 9개의 기본 박스가 주어진 것이다. 또한 sliding window로 각 픽셀마다 확인함으로 총 anchor의 갯수는 feature map이 H*W라면 H*W*k개가 나오게 된다.

이 k개의 박스를 조사할때 reg단계에서는 4k의 output, cls 단계에서는 2k의 output이 나오게 된다. reg 단계에서는 (tx, ty, th, tw)로 나오고 cls는 (object 존재, object 없음)으로 나오기 때문이다. 사실 cls 단계는 logistic regression으로 k개의 output만 나오게 할 수 있는데 편의를 위해 2k의 softmax layer로 돌린 결과를 이용한다. -> 편의?
이 anchor들은 translation invariant 특성을 가지고 있다. 즉 위치가 이동해도 출력에는 영향을 미치지 않는 것이다. trans invariant의 장점은 파라미터 공유를 통해서 위치에 관계없이 특징을 추출해서 파라미터의 수를 줄일 수 있다는 것이다. 만약 translation variant하면 위치에 따라서 같은 물체여도 필터를 다르게 잡아야 한다. 실제로 기존의 MultiBox method에서는 k-mean을 이용해 박스를 생성했는데 대략 800개의 anchor들이 생성되었다고 한다. 하지만 여기서 제시하는 방법은 오직 9개의 anchor로 모든 것을 해결할 수 있다. 또한 파라미터들이 줄었기때문에 overfitting의 문제도 해결할 수 있게 된다.
이 특성이 일어난 이유는 conv net을 사용하였기 때문이다. 아래 그림처럼 CNN은 하나의 image내에서 서로 다른 필터들을 연산해서 결과를 낸다. 그리고 그 필터들은 연산과정중에는 항상 같은 값을 가지기 때문에 즉 weight sharing을 함으로 object의 위치와 관계없이 특정 패턴을 학습할 수 있다.

위의 빨간색 필터는 삼각형 추출이고 파란색 필터(k번째)는 직선 추출인데 이미지가 직선을 나타냄으로 k번째 필터의 결과가 큰 값을 가지게 된다. 사실 CNN 자체는 translation varaiant한데 그 이유는 아래 처럼 convolution의 결과가 위치에 따라 달라지기 때문이다.

하지만 이것은 softmax를 통해서 invariant하게 바뀐다.

결국 마지막에 softmax를 통해서 label만큼의 노드를 통해서 결과가 나옴으로 위치가 어디있던지 직선이면 직선 삼각형이면 삼각형이라고 나오는 것이다.
anchor들은 또한 multiple scales로 다루어지는데 이러한 multi-scale prediction의 방법은 3가지가 있다.
1) 첫번쨰는 image/feature pyramid에 기반한 방식이다. 이방식은 image 자체를 여러 비율로 resize 시켜서 그것의 feature map을 계산하는 방식이다. image를 resize하고 convnet에 돌리고를 반복해야되서 time consuming한 방법이다.

2) 두번째는 feature map상에서 sliding window를 통해 다향한 filter들을 계산해보는 것이다. 이 방법은 pyramid of filters라고 하는데 주로 지금까지는 첫번째와 두번째의 방법을 결합하여 사용하였다.

3) Faster R-CNN에서는 anchor를 이용한 새로운 방법을 제시하였다. pyramid of anchors인데 single scale의 feature map을 사용하고 single size의 filter를 사용하고 이 feature map의 ratio와 scale을 바꾸는 방식이다.

그리고 이 방식은 굉장히 효율적인 것으로 밝혀졌다.
1-2. loss function
anchor마다 binary class label을 붙이는데 positive label은 두가지 경우에 붙인다. 1) ground truth box와 highes IoU를 가진 anchor 2) ground thruth와 IoU가 0.7이상인 박스의 경우이다. 사실 2)만 해도 되긴하지만 특수한 경우 positive label이 아예 안잡힐 수 있기때문에 1)의 경우도 고려하는 것이다.
negative label은 IoU 0.3이하의 경우이고 그 이외의 경우는 사용하지 않는다.
loss function의 식은 아래와 같다.

pi : object인지 아닌지 / pi* : ground truth(GT), 1이면 anchor가 positive, 0이면 negative
Lcls : 크로스 엔트로피 / Lreg : smooth L1 loss

ti : predicted bounding box의 4개의 파라미터 / ti* : GT
이때 4개의 파라미터는 tx, tw, ty, th로 구성된다. 이들은 box의 중심인 x,y 좌표 이동정도와 box의 가로, 세로의 비율조정과 관련있다. box를 조정할때 bx = px+pw*tx, by = py + ph*ty, bw = pw*exp(tw), bh = ph*exp(th)
로 조정하게 되는데 여기서 tx, tw, ty, th에 대한 식을 구해서 아래의 식을 사용하게 된다.

Ncls : minibath의 수 / Nreg : anchor location의 수
λ : Ncls와 Nreg를 맞추기 위해 대략 10정도 곱한다.
또한 k개의 bounding box regressors가 학습될때 이 regressor들이 weight sharing이 일어나는 것이 아닌 각각의 regressor들이 학습이 된다.
1-3. Training RPN
RPN을 학습할때는 image-centric sampling strategy를 사용하게 된다. 미니배치들에서 가장 많은 positive, negative anchor를 가지고 있는 하나의 이미지 선정한다. 이 자체를 loss값을 구하는 것이 아니라 positive, negative의 비율을 1:1로 동일하게 맞추어 random하게 뽑은뒤에 loss, backprop을 실행한다. 이때 부족한 부분은 padding을 통해 처리한다.
2. Sharing Features for RPN and Fast R-CNN
전반적인 구조는 RPN에서 나온 region proposal을 두번째 stage에서 Fast R-CNN으로 detect하는 것이다. 이때 독립적으로 훈련된 이 두단계를 나누지 않고 conv layer들을 공유하도록 해야하는데 이때 다음 3가지의 방법이 제시된다.
1) Alternating Training
RPN을 먼저 학습한 다음 그것을 Fast R-CNN으로 훈련한다. 그리고 Fast R-CNN으로 tuning 된 것이 RPN을 초기화할때 사용된다. 이 방법은 이 실험의 주된 방법으로 사용되었다.
1. RPN을 훈련시킨다. 이때 ImageNet pre trained model을 사용하였다.
2. Fast R-CNN으로 detection area를 훈련하는데 이때 1에서 얻은 proposal을 이용한다.
3. 2의 detector network으로 RPN을 초기화한다. 이때 shared conv layer를 고정하고 오직 RPN에만 있는 layer를 건드린다.
4. 3과 마찬가지로 shared conv layer를 고정하고 오직 Fast R-CNN에만 있는 layer를 건드린다.
2) Approximate joint training
RPN과 Fast R-CNN을 훈련할때 하나의 네트워크로 합친다. forward pass에서 region proposal이 고정된체로 Fast R-CNN단계로 들어간다. 그리고 back prop단계에서 RPN loss와 Fast R-CNN단계의 loss값이 합쳐져서 진행된다. -> 이부분이 이해가 잘 안갔지만 아마 snapping을 해서 back prop이 안되는 것이라고 생각된다.
이 방법은 실행하기는 쉬우나 region proposal 단계가 고정되기 때문에 proposal box의 coordinate 미분값이 생략이 된다. 그래서 approximate라고 한다.
3) Non-approximate joint training
Fast R-CNN단계에서는 input으로 proposal box와 feature map을 input으로 사용된다. 2)와 다르게 coordinate의 미분을 위해서 이때는 RoI warping을 이용한다.
3. Implementation Detail
몇개를 간추리면
1) 범위를 넘어가는 anchor는 무시한다.
2) 너무 겹치는 anchor들은 NMS로 정리한뒤 top n ranked proposal region을 사용한다.
4. Experiments
실험으로 얻어낸 사실들을 정리해보았다.
1) shared network의 효과를 입증하기 위해 4-stage에서 2번재까지만 하고 각기 다른 network로 두개의 stage를 학습시켰을때 정확도가 낮아짐을 보였다.
2) RPN에서 100개의 proposal과 6000개의 proposal의 정확도를 비교해보았을때 거의 차이가 없었다. 따라서 NMS는 사용해도 괜찮다.
3) reg layer를 없에고 실험을 해보았을 때 mAP가 떨어짐을 확인할 수 있다. 이는 Fast R-CNN단계에서의 bounding box regression이외에 RPN단계에서의 proposal이 중요하다는 것이다.
4) RPN+VGG와 Seletive search를 비교하였을때 전자가 더 우수하였다. 이는 selective search는 online으로 이루어지지 않고 pre defined된 반면에 RPN은 네트워크 상에서 actively train되기 때문이다.
5) 3 scale 3 ratio가 가장 큰 효과를 보여주었다. 사실 아래의 표에서 3 scale 1 ratio나 scale 3 ratio나 차이가 거의 없었따. 하지만 flexible을 위해 3 scale, 3 ratio를 선택하였다.

6) loss function에서의 λ는 10이 가장 적절하였다. 하지만 넓은 범위에서 그리 중요한 하이퍼 파라미터는 아닌 것 같다.
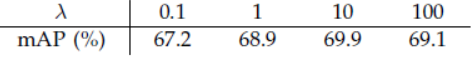
7) recall to IoU 그래프를 selective search, RPN, Edge Box에 대해서 실험했을때, 300개의 proposal일때의 RPN이 굉장히 우수한 결과를 보여주었다.

5. CONCLUSION
RPN이 효과적이고 정확한 region proposal generation이라는 것을 보였다. conv layer를 공유하는 방식으로 region proposal을 거의 cost free로 만들었다. 이 네트워크가 또한 통합된, 딥러닝 베이스 모델이여서 real time으로 빠르기도 하다.
'논문 정리' 카테고리의 다른 글
| You Only Look Once: Unified, Real-Time Object Detection (0) | 2021.02.26 |
|---|---|
| Training Region-based Object Detectors with Online Hard Example Mining (0) | 2021.02.24 |
| Dropout : A Simple Way to Prevent Neural Network from Overfitting (0) | 2020.12.29 |
| Deep Learning (0) | 2020.12.27 |