Training Region-based Object Detectors with Online Hard Example Mining
1. Introduction
Object detection는 reduction이라는 방법을 통해 image classification 방법을 이용한다. 즉 박스안에 물체가 있는지 없는지 같은 classificaition을 이용하는 것이다. 이러한 방법은 다만 문제가 있었는데 라벨이 붙은 물체와 그렇지 않은 background 물체의 수의 차이로 인해 제대로된 학습이 잘 안된다는 것이였다.
즉, 하나의 물체에는 여러개의 bounding box가 나타나게 되는데 그 과정에서 비슷한 크기의 다른 bounding box들도 생성이 되고 그것들중 배경과 물체를 구분을 해야한다. 하지만 우리가 가진 데이터는 아무래도 물체의 데이터가 background 데이터보다 월등히 적기때문에 False Negative, 즉 물체를 찾으려고 했는데 못찾는 경우가 나오는 것이다.
이를 극복하기 위해 bootstrapping(요즘은 hard negative mining이라고 더 많이 사용한다)이 있다. 우선 hard negative란 object detection에서 많이 사용하는 단어인데 실제 negative이지만 positive라고 잘못예측하기 쉬운 데이터를 이야기한다.

즉 위의 사진에서 빨간색부분이 False positive이고 이들은 우리눈에는 모두 다른 것으로 보이지만 머신상에서는 얼굴과 비슷하게 검출이되어 얼굴이 아니지만 positive라고 나온 것이다. bootsrapping은 이를 해결하기위해 이런 hard negative 데이터를 모은다. 그리고 이 데이터들을 기존의 데이터에 추가해 다시 학습시키면 false positive에 강해지고 오류가 많이 줄어들어 아래 사진의 결과를 얻을 수 있는 것이다.

이러한 hard negative mining방식은 R-CNN, SPPnet등에 사용되었다.
하지만 Fast R-CNN 이후로는 사용되기 힘들어졌다. Hard negative mining방식은 다음과 같이 두개의 알고리즘으로 운영되는데 (1) fixed model이 새로운 샘플을 찾아서 active training set에 넣는다. (2) 모델이 이 active training set을 기반으로 학습한다. 하지만 SGD를 이용해 학습하는 Fast R-CNN의 경우 SGD가 수천개의 iteration이 필요한데 이렇게 freeze하고 학습하고 하는 과정에서 freeze에서는 학습을 할 수 없기에 굉장히 시간 낭비이다.
그래서 제시한 것이 purely online form의 hard example selection이다. 이를 OHEM이라 한다. 이것을 사용했을때의 장점은 아래와 같다고 한다.
1. region-based Convnets에서 사용했던 몇개의 heuristic한 하이퍼 파라미터들을 없엔다.
2. mean average precision의 효과를 상승시킨다.
3. training set가 larger and difficult할 수록 효과를 본다.
2. Overview of Fast R-CNN
우선 Fast R-CNN(FRCN)은 아래의 구조를 가지고 있다.
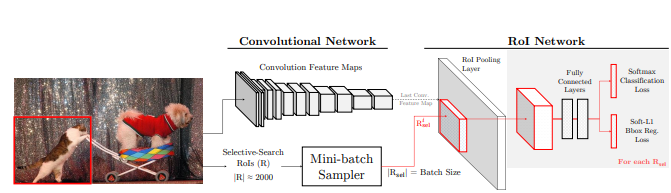
두개의 네트워크가 있는데 첫번째가 이미지의 feature map을 보여주는 Convolution network이고 두번째가 RoI pooling Layer, 몇개의 fc layer, classification loss와 bounding box regression loss layer로 구성된 RoI Network이다.
이 논문은 기본 뼈대가 FRCN으로 이루어져있는데 그 이유가 (1) SPPnet이나 MR-CNN과 다르게 FRCN은 conv newtork를 고정을 시키지 않고 훈련이 가능하고 (2) conv net과 RoI net으로 구성된 것이 응용하기가 용이하고 (3) RoI가 훈련과정중 동떨어진 것이 아닌 online으로 구성되있는 점이다.
FRCN은 하지만 경험적인 heuristic한 측면이 있다. 예를들어 foreground의 라벨은 IoU가 ground truth box와 0.5이상정도 되었을때 붙이는 것이 좋고, background 라벨은 0.1~0.5정도의 IoU가 되었을 때 붙이는 것이 좋고 foreground와 background의 비율은 1:3정도로 하는 것이 좋다는 것이다. 이러한 경험적인 측면은 수많은 실험 끝에 나오게 됨으로 많은 시간이 걸리게 된다. OHEM은 이러한 부분을 해결하려고 하였다.
3. Our Approach
OHEM은 위에서 나온 hard example mining을 SGD용으로 바꾼 것이다. 여기서의 핵심은 각각의 SGD iteration에서의 샘플은 몇개의 이미지만 있지만 그 각각의 이미지는 수천개의 RoI 샘플을 가지고 있고 여기서 hard sample을 경험적인 측면의 데이터를 이용해 몇대 몇으로 쪼개는 대신 그 것들 중에서 hard sample을 직접 고르는 것이다.
그 과정은 아래와 같다.
1) conv feature map을 conv network를 이용하여 계산한다.
2) RoI 네트워크는 sampled minibatch를 사용하는대신 이 feature map과 모든 input RoI들을 이용한다.
3) 위에서 구한 결과의 loss 값을 정렬한뒤에 B/N개의 sample들을 선택하고 backward를 진행한다.
어차피 대부분의 연산은 conv network에서 이루어지고 이것은 공유되고 backward는 모든 RoI들에 대해 하는 것이 아닌 선택된 몇개로만 함으로 연산량의 차이는 기존의 방식과 차이가 거의 없다.
하지만 비슷한 영역의 RoI는 loss값도 비슷할텐데 그로인해 중복해서 sample에 들어갈 수 있다. loss가 double counting이 될 수 있는데 이를 위해 NMS로 중복되는 영역을 제거해준다.
이를 FRCN에 넣으려면 기존의 loss layer를 hard example selection을 할 수 있게 수정해주면 된다. 간단히 생각하면 상위 loss들을 hard RoI로 두고 나머지를 non-hard RoI로 두어 0으로 만들면 계산이 안되고 hard RoI만 계산이 될 것이다. 하지만 이방법은 backprop에서 여전히 non-hard RoI가 살아있어 메모리를 차지하는 문제가 발생한다.
이를 해결하기 위해 아래의 방법을 사용하였다.

read-only layer를 만드는 것이다. 이 layer는 RoI network이긴 하지만 오직 forward만 할 수 있다. FRCN과 결합한 과정은 아래와 같다.
1. Conv network를 이용해 feature extraction을 한다.
2. 같은 이미지를 selective search 알고리즘을 적용해 region proposal을 추출한다.
3. RoI Pooling을 2에서 얻은 모든 RoI에 대해 진행한다. -> 이때 RoI의 수만큼의 feature map이 생성된다.
4. read-only layer에서 각 RoI들에 대해 loss값을 구한다.
5. Hard RoI Sampler를 이용해 상위 몇개의 RoI들만 선택한다.
6. 5에서 얻은 선택된 RoI들을 다시 max pooling을 해서 feature map을 얻는다.
7. 마찬가지로 RoI Network를 이용해 loss를 계산후 이 결과를 이용해 backprop을 한다.
OHEM의 방법을 적용하면 sampling이 필요하지 않기때문에 모델의 학습을 빠르게 진행할 수 있다. 만일 어떠한 이미지의 특정 class가 샘플로 선택하지 않았다면 그 class는 backprop을 거의 하지 못해 loss가 상승할 것이다. 따라서 그 다음 iteration때 그 class가 선택될 가능성이 높아지는 것이다. 이로인해 전에는 직접 사람이 개입해 몇대 몇으로 나누었는데 그 과정을 없엘 수 있다.
4. Analyzing online hard example mining

1) OHEM vs heuristic sampling
우선 FRCN에서 heuristic 부분의 효과를 확인하기 위해 background의 threshold를 0.1로 둔것과 0으로 둔것의 차이를 확인해 보았다. 그 결과 mAP가 2.4정도 떨어진 것을 확인할 수 있다.
이번에는 OHEM을 이용한 결과이다. 12, 13번의 결과를 보면 2.4포인트정도 상승한 것을 확인할 수 있다.
2) Robust gradient estimate
일반적으로 한 배치당 2개의 이미지를 사용한다. 하지만 OHEM에서는 같은 이미지에서 나오는 loss가 높은 것들만 골라서 훈련시키기때문에 한 이미지에서 샘플들이 다 나올 수 있는 상황이 발생할 수 있다. 그래서 이번에는 배치당 1개의 이미지를 이용해서 실험을 해보았다.
OHEM을 사용하지 않았을때는 1포인트정도 떨어졌다. 하지만 OHEM을 사용했을때는 위의 11번 처럼 거의 차이가 ㅇ벗는 것을 확인할 수 있다. 따라서 경우에 따라서는 GPU 메모리를 위해 1개의 이미지만을 배치에 넣어도 상관없음을 알 수 있다.
3) Why just ahrd examples, when you can use all?
OHEM은 hard example을 선별하여 그것을 이용해 훈련을 진행한다. 하지만 어떻게 생각해보면 모든 RoI들을 이용해도 된다. 어차피 easy example들은 쉽게 판별이 가능해서 loss가 낮고 따라서 gradient descent에 그리 큰 영향을 끼치지 않을 것이기 때문이다.
7-10의 결과는 FRCN의 mini batch를 키우고 bg_lo를 0으로해서 최대한 그 상황에 맞춘 결과이다. 원래 값인 1,2결과보다 1포인트정도는 올랐지만 OHEM이 더 우세하였고 속도였이 선별된 몇개만을 이용해 backprop을 하기 때문에 OHEM이 우세하다.
4) Better optimization
loss값이 낮을 수록 좀더 잘 훈련된 결과라 볼 수 있다.

위의 그래프에 따르면 보라색인 OHEM이 가장 우세한 것을 볼 수 있다.
5. Conclusion
OHEM은 heuristic한 부분을 줄이고 자동으로 hard example이 선택될 수 있게 한다. 이로인해 훈련과정이 단순해지고 PASCAL등에서 좋은 결과를 보일 수 있었다.
또한 이 논문에서는 FRCN을 이용하여 하였지만 region-based ConvNet detector를 이용하는 모델이라면 모두 적용이 가능하다.