Sequence to Sequence Models : Attention Models /Lec 13.
전 강의에서는 input이 output보다 더 긴 경우의 sec to sec를 보았다. 이번에는 output이 더 긴 경우를 보려고 한다. 기본적인 원리는 아래와 같다.

우선 input W1,W2,W3을 통해 네트워크를 학습시킨 다음 마지막 input인 W3이우헤 네트워크는 각 symbol에 대한 확률인 y를 만든다. 거기서 output을 고른다음 그것을 W4라고 한다.

그 W4를 input이라고 생각하고 다음 단계에서 같은 것을 반복한다.

이를 계속 반복하면 된다.

그렇다면 언제까지 반복하면 될까? 이를 위해 새로운 symbol 2개를 추가한다. 하나는 <sos>이고 다른 하나는 <eos>이다. <sos>는 Start Of Sentence이며 문장의 시작을 의미하고 <eos>는 End of Sentence로 문장의 끝을 의미한다. 이를 이용한 예를 보이면
1. I ate apple : 이것은 문장의 중간을 의미한다.
2. <sos> I ate apple : 이것은 문장의 시작부분을 의미한다.
3. I ate apple <eos> : 이것은 문장의 끝부분을 의미한다.
4. <sos> I ate apple <eos> : 이것은 완벽한 full sentence를 의미한다.
따라서 위의 과정을 <eos>가 나올때까지 반복하면 된다. 이러한 구조를 Delayed sequence to sequence라고 한다.

이 모델의 결점 한가지는

위의 구조와 달리 output이 그 다음 input으로 들어가지 않는 다는 것이다. 이렇게 되면 만약 파란색이 a 또는 an이 나와도 그 다음 output은 이 a와 an을 반영하지 않기 때문에 예를들어 an에서 elephant가 나왔다면 a에서도 elephant가 나올 것이다. 그래서 이 모델에서 output을 다음 input으로 반영하는 것을 추가 해야 한다.

반영한 이 구조를 self-referencing sequnece to sequence라고 한다. 그러면 이 구조로 어떻게 번역을 하는지 살펴보자.

우선 파란색 부분은 번역하고자 하는 문장을 받아들이는 부분이나 <eos>의 hidden layer에서는 이 문장의 모든 정보를 담고 있다..

이제 이 두번째 RNN이 작동을 한다.

첫번쨰 RNN의 hidden layer의 정보를 읽어 첫번째 단어를 생성한뒤 그 단어와 hidden layer를 이용해 다음 단어를 <eos>가 나올때 까지 계속 생성한다.

위의 과정에서 파란색 박스를 encoder, 빨간색 박스를 decoder라고 한다. encoder는 input을 받아들여 그 input을 hidden representation으로 바꾼다. decoder는 input에서 생성된 hidden representation을 이용해 output을 생성한다. 이 과정에서 앞의 강의에서 보았듯이 one-hot encoding이 사용될 것인데 이는 매우 비효율적이라고 하였다. 따라서 projection을 통하여 one-hot vector의 공간낭비를 줄일 수 있다. 또한 layer를 한개만 쌓는 것이 아니라 여러개를 쌓아도 무방하다.


그렇다면 이 네트워크는 output을 어떻게 생성하는 것일까? 이전에 했던 모델들과 다를 것이 없다. input에 받은 것을 토대로 symbol들에 대해 각각의 확률을 매기는 것이다. 이를 수식으로 나타내면 아래와 같다. N개의 전체 input과 그전에 나온 output들을 바탕으로 현재 symbol에대한 확률을 나타내는 것이다.

그리고 우리는 most likely ouput을 찾는 것이다. 이는 각각의 시간에서 하나씩 골라 만든 ouput들의 확률이 가장 높은 것을 고르는 것이다. 고른 문장의 확률이 이라면 우리가 찾아야 하는 것은
이다. 이를 찾는 방법은 가장 먼저 떠오르는 것은 각각의 시간에서 확률이 가장 높은 것들을 뽑아서 만드는 방법일 것이다. 이를 greedy drawing이라 한다. 하지만 이방법은 각각 optimal이지만 전체적으로 보았을때는 optimal이 아닐 수 있다. 아래의 예시를 보자.
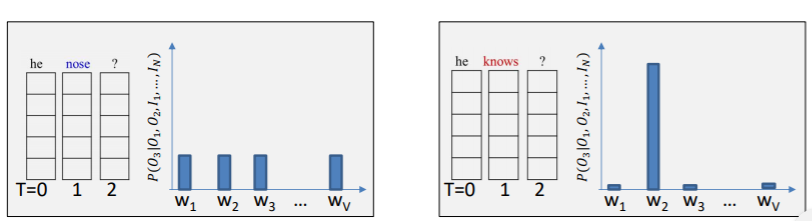
위는 영어 speech를 문자로 바꾼 것이다. 듣기에는 nose와 knows 비슷하게 들었을 것이다. 그러나 t=2일때 nose가 optimal이여서 그것을 골랐고 t=3을 보았더니 symbol들이 다 비슷한 probability를 가졌다. 하지만 t=2일때 optimal이 아닌 knows는 t=3일때 명확한 하나를 고를 수 있었고 결과적으로는 knows를 고른 상태가 optimal이였던 것이다. 이렇게 하나를 잘못고르면 그 잘못 고른게 다음 input으로 들어가기에 전체적인 네트워크에 혼란을 줄 수 있다.
그래서 다른 방법을 생각해본게 고르지말고 랜덤으로 뽑는 것이다. 하지만 당연히 이방법도 random이 most likely를 준다는 보장이 없기에 불가능 하다.
이 문제를 해결할 방법은 multiple choice를 하는 것이다. 모든 방법을 보는 것이다.

물론 이렇게 보면 가장 정확하겠지만 현실적으로 계산량이 너무 많아지기에 불가능하다. 따라서 위에서 몇개까지만 살리고 나머지는 버리는 pruning을 한다. 아래 예시에서는 top 2만 살리도록 한다. top을 고를때는 그때 그시간만 보는 것이 아닌 그동안의 결과의 곱들을 이용해서 top을 따진다.

만일 아래처럼 하나의 가지가 <eos>가 나온다면 그 가지는 종료하고 나머지를 계속한다. 그래서 모든 문장을 얻어내면 그때 optimal을 고르는 것이다.

이 네트워크의 training방식은 다음과 같다. 우선 forward pass로 output을 알아낸다. 그다음 각각의 output과 target을 비교하여 divergence를 얻어내고 업데이트를 진행한다. 보통은 모든 output에 대하여 하지 않고 SGD를 적용하여 랜덤하게 몇개의 단어를 뽑아내어 업데이트를 진행한다.

위의 네트워크를 좀더 향상시키는 방법은 input을 거꾸로 두는 것이다.

아니면 encoder의 마지막 hidden state를 decoder의 모든 hidden state의 input으로 넣어도 효과가 좋다.

이제

이 네트워크의 문제점 하나를 파악해보자. 문제점은 저 빨간색 박스, 즉 encoder의 마지막 hidden state에 너무 많은 정보가 들어있다는 것이다. 이 hidden state에는 모든 input의 정보가 들어있다. 하지만 output은 그 모든 정보가 필요로 하는 것이 아닌 아래처럼 일부의 input과만 관련이 있다.

위에처럼 구성하면 예를 들어 gegessen은 ate라는 정보만 필요한데 I, ate, an, apple이 모두 섞여서 정작 ate라는 정보는 흐려질 수 있다. 그래서 나온 것이 Attention model이다. 이는 현대의 sec to sec에 굉장히 많이 사용되는 모델이다. 구성은 아래와 같이 된다.

모든 input의 hidden state가 weighted combination되어서 각각 ouput의 input으로 들어가는 것이다. 따라서 이때 decoder의 input은 바로전의 output, 바로 전의 hidden state value 그리고 weighted combination이 되는 것이다. 그리고 이떄의 w는 encoder의 hidden state와 decoder에서 바로 전의 hidden state s의 함수가 된다. 이를 raw weight라고 한다.

그리고 이 raw weight를 distribution형태로 나타내 어떤 것을 선택할지 확률적으로 표시한다. 이를 위해 softmax를 이용한다. 따라서 raw weight를 e, actual weight를 w라 하면

가 된다. 이때 i는 input의 번호이고 t는 output의 번호이다. 그리고 이때 g는 아래처럼 여러가지 방법으로 할 수 있다.

이것을 실제로 적용해보자.

encoding을 한뒤 마지막 hidden state를 decoder의 initial hidden state로 넣는다. 이때 크기가 다르다면 파라미터를 곱하여 크기를 맞춰준다. 이제 각각의 raw data를 구한다. 그리고 그것을 토대로 actual weight를 구한다. 그리고 이를 attention이라고 한다. 이 weight가 어디에 집중할 지 알려주기 떄문이다.

그다음 이 w를 decoder의 input으로 삼아서 바로 전의 decoder hidden state와 함께 계산해 ooutput의 distribution을 구한다.
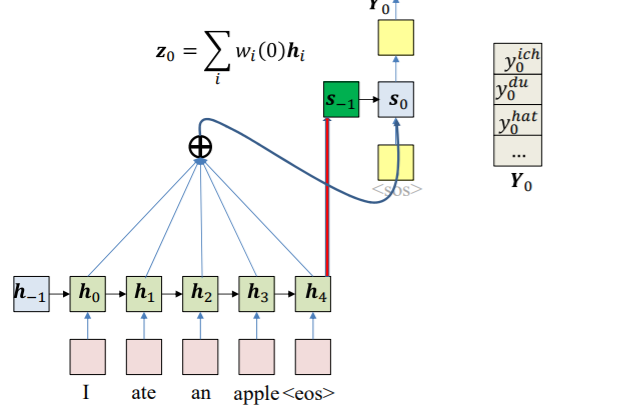
이 과정을 반복하면 된다.



output을 만드는 것은 위에서 한 것 처럼 multiple choice를 이용한다.



training역시 전에와 다를 것이 없다. 각각의 output에대한 divergence를 구하여 업데이트 하면 된다.

그렇다면 이 attention은 어떤 것을 배우는 것일까?

아래는 각 단어에 따른 attention을 보여준다. 하얀색이 어디에 집중하고 있는지를 알려준다.
이 모델을 좀더 효과적으로 바꾸는 방법이 있는데 틀린답을 일부로 알려주는 것이다.

이렇게 때떄로 틀린 답을 input으로 넣으면 틀린 해석을 해도 바로 잡을 수 있도록 할 수 있다. 이를 Teacher forcing이라고 한다. 또한 encoder에는 bidirectional processing을 넣는 것이 더 효율적이다.