2021. 2. 20. 22:57ㆍ관심있는 분야
1. Detecting Single Object
가장 기본적인 구조는 다음과 같다. 먼저 Transfer learning을 이용한다. 그다음 마지막 벡터를 이용해서 물체 classification과 box를 검사한다. 그리고 이 둘의 결과를 weighted sum하여서 loss값을 구한다.

하지만 이방식은 single object일때는 상관없지만 여러개의 object가 있다면 box coordinate를 하나하나 다 구해야 하기때문에 파라미터 수가 많아져서 계산이 불가능해진다. 따라서 Multiple object detection을 위해서 새로운 기법이 고안이 되었다.
2. R-CNN : Region-Based CNN

기본적인 구조는 우선 1) proposal method를 이용하여 RoI를 구하고 2) 그 것을 미리 정한 크기로 만든다. 여기서는 224*224로 하였다. 3) 그리고 각각을 Conv Net으로 돌려서 4) 그 결과를 Classification하고 4) box의 위치인 Bbox도 수정한다.
Bounding Box Regression
우선 Bounding box는 4개의 파라미터로 구성된다. (px, py, ph, pw)인데 각각 박스의 중심 x,y 그리고 가로와 세로이다. 이것을 4개의 transform parameter로 수정하는데 각각이 (tx, ty, th, tw)이다. 만약 그 수정된 결과가 (bx, by, bh, bw)라면 수정되는 과정은 아래와 같다.
박스의 중심 bx = px+pw*tx, by = py + ph*ty이고 가로와 세로는 bw = pw*exp(tw), bh = ph*exp(th)로 구한다.
이 과정을 Bounding box regression이라고 한다.
Itersection over Union(IoU)
Bounding Box Regression을 진행한다음 ground truth와 비교를 해야하는데 어떤 기준으로 해야할까? 이를 위해 IoU를 사용한다. 말그대로 겹친 부분의 비율을 확인하는 것이다.

위에 사진처럼 주황색부분인 Area of Intersection을 보라색부분인 Area of Union으로 나누면 된다.

보통 IoU>0.5이면 부족하다지만 비슷하다고 보고, >0.7이면 적당히 좋고, >0.9이면 거의 일치한다고 본다.
Non-Max Suppression(NMS)
하지만 실제로 Object detection을 할때에는 하나의 output이 나오는것이아닌 하나의 물체마다 비슷한 박스들이 여러개 나오게 되고 이중에서 하나를 선택해야한다.
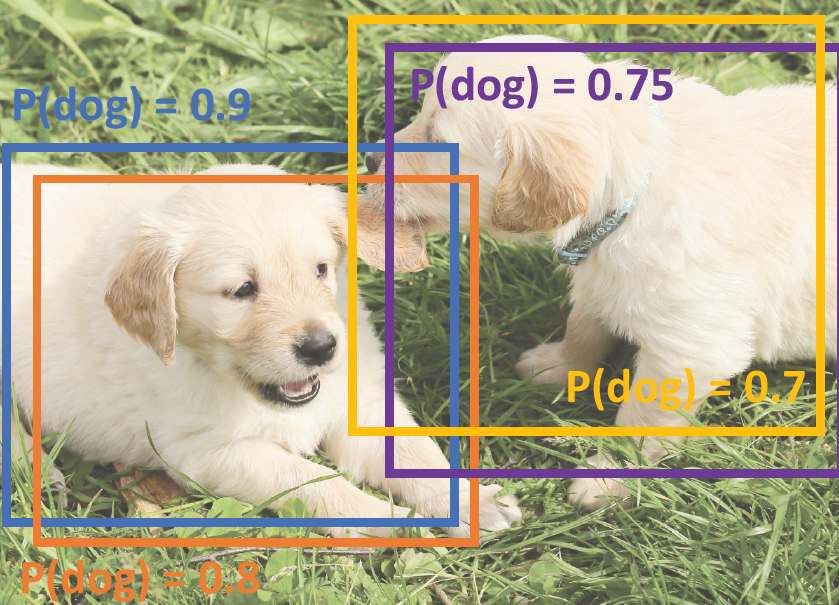
이를 위해서 post process인 NMS를 실행해주는데 그 과정 greedy 방식으로 아래와 같다.
1) 모든 박스들이 담긴 집합에서 가장 높은 점수의 박스를 고른다. -> 이 박스를 결과에 넣는다.
2) 그 박스와 다른 박스들의 IoU를 계산한뒤에 threshold를 넘으면 제거한다.
3) 모든 박스들이 담긴 집합가 빌때까지 반복한다.
위의 과정을 진행하면 아래의 결과가 나오게 된다.
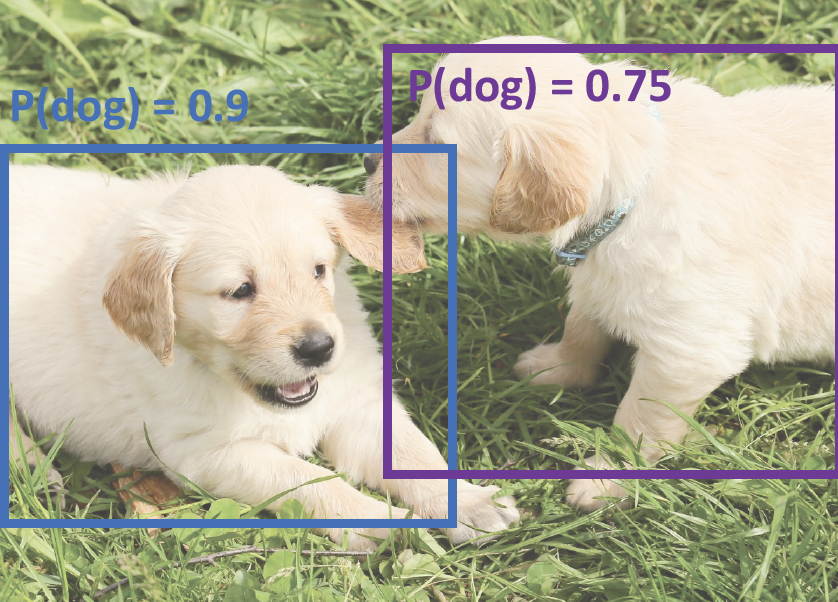
하지만 이 방법은 서로다른 물체들의 박스가 너무 많이 겹칠 때 문제가 된다.

위의 경우에서 세개의 말은 전부 다른 object이다. NMS를 실시할때 검정색 박스가 선택되고 빨강과 파랑과의 IoU를 구하는데 겹치는 부분이 많다보니 threshold를 넘어서게 되어서 빨강과 파란 박스가 사라지는 경우가 발생할 수 있다. 이때문에 soft-NMS를 사용한다. 이것은 NMS를 사용할때 threshold를 넘어서면 아예 제외를 해버리는데 이대신 confidence를 줄여서 여전히 겹치는 박스들이 살아있게 한다.
Mean Average Precision(mAP)
object detect를 한 뒤에 그 결과를 평가하는 지표로는 mAP를 사용한다. 그 방법은 아래와 같다.
1) object detecor를 이용해 모든 이미지들을 돌린다.
2) 각각의 카테고리별로 Average Precision(AP)를 계산한다. -> 이것은 Precision, Recall Curve의 넓이이다.
예를들어보면 우선 각각의 detection의 결과를 내림차순으로 정렬한다. 그다음 가장 큰 점수를 받은 결과와 Ground truth의 IoU를 비교해 0.5보다 크다면 true positive로 설정하고 그렇지 않으면 true negative로 설정한다.

이 경우 IoU가 0.5보다 큼으로 true positive가 되고 이때의 Precision = 1/1, Recall은 1/3이 된다. 그리고 이것을 그래프에 옮긴다.
참고로 Precision은 우리가 detect한 것 중 실제로 true인 비율이고 Recall은 Ground truth중에 우리가 hit한 비율이다.

이를 반복하면



위의 결과에 의해
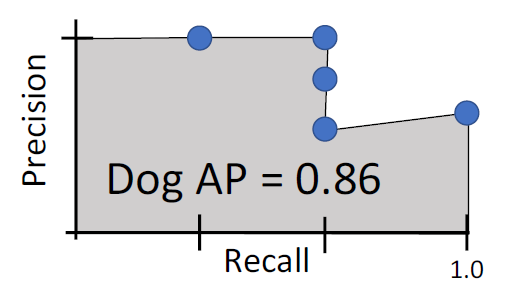
강아지의 AP가 0.86이 나오게 된다. 그리고 이 것을 모든 카테고리별로 진행한뒤에 평균을 내면 된다.
실제로는 threshold 0.5로만 하기에는 무리가 있다. 0.5는 IoU에서 그저 그런 수준이기 때문이다. 따라서 0.5, 0.55, ..., 0.9등으로 다양한 threshold를 잡은뒤에 그 모든 것을 평균을 낸다. 이방법을 COCO mAP라고 한다.
하지만 R-CNN의 단점은 proposal 단계에서 대략 2000개정도의 box를 생성하는데 이를 일일이 다 Conv Net에 넣어서 regression을 진행해야 한다. 그래서 굉장히 느리다.
이로인해 새로운 방법이 제안되었다.
'관심있는 분야' 카테고리의 다른 글
| Object detection 3 (0) | 2021.02.21 |
|---|---|
| Object Detection 2 (0) | 2021.02.21 |